
The Binding Brief: Antibody Goof up, AI x Bio Thoughts, and Disulfide Bond Check
No. 04 | May 27, 2026

Welcome to the fourth edition of the ‘The Binding Brief’, a weekly newsletter dropping in your inbox every Wednesday where we shall journey together into the world of antibodies.
If you haven’t checked out my content library yet, it includes all the bits and bobs of information covered on The Binding Brief to date, categorized by theme!!!
This week, we have some exciting things to discuss.
Raw Data: What’s the real role of scientists in this AI world?
This Week’s Deep Dive: How do you choose a PhD research topic?
Bench Notes: A quick way to check if your protein has disulphide bonds
Antibody Spotlight: Antibodies used against p16INK4a or p16-ARC?
In Silico: What do we know so far in de novo protein design?
Antibody Term of the Week: Native versus recombinant antibodies

1. The Raw Data
As I write this, I just finished Day 1 of the AI x Bio conference by Wellcome Connecting Science (#AIxBio26). Today’s sessions covered solving the DNA and RNA gene regulatory code, as well as solving proteins and protein data.
The day opened with a fantastic keynote by Pushmeet Kohli (Google DeepMind) on leveraging AI to advance biology. He spoke about the sheer complexity of the human body making biology a perfect application for AI, ranging from understanding proteins (structure, function, binders) to decoding the genome (missense and non-coding variants) and building a virtual cell. All of this underscored DeepMind's core purpose: to build AI responsibly, for the benefit of humanity.
I came into this conference with a specific mindset that I wouldn't get swept up in the hullabaloo of AI, but instead ask whether AI is actually the right tool for a specific biological problem. What struck me is that every single presenter embodied what I'd call "cautious optimism." Nothing over-the-top, which is exactly what the field needs right now. It was a perfect blend of using AI to fast-track data output, paired with rigorous checks and balances in validating it.
AI is progressing faster than the human mind can fully comprehend. Pushmeet put it well:
”The real role of scientists now is not to ask the "how" (which is what we're trained to do) but rather the "what."
What is an AI hallucination, and what is a real result?”
That discernment is where scientists hold their credibility.
Check out this big news that was announced today at the conference. ⤵️ Looking forward to Days 2 and 3.

2. This Week’s Deep Dive
No one tells you how different a Masters program is from a PhD. Even if your Masters degree was a research-based one, a PhD is a whole different ballgame. It feels like the next step in a logical progression of education, but that is far from the truth. In a Masters program, you sign up for the pool membership and by the end of it, you are taught the rules and regulations of the club and you learn where to get the towels from. In a PhD, you are expected to know all of it and dive directly into the deep end of the pool. Forget the learning to swim part. In a nutshell, your PhD teaches you how to do research and become an independent thinker.
A common question I get from students started out their PhD - “how do I choose my PhD research topic?” The banal answer is - find a knowledge gap in the topic of your interest and that becomes your PhD. But the real question comes next, “how do I find a knowledge gap in a field that is quite new to me?” It seems like and it is a daunting process. But you are not alone in thinking so. There are some tips and tricks to navigate this and I have put together a brief on how YOU can choose your PhD research topic and be happy with it as well. Check it out.

3. Bench Notes
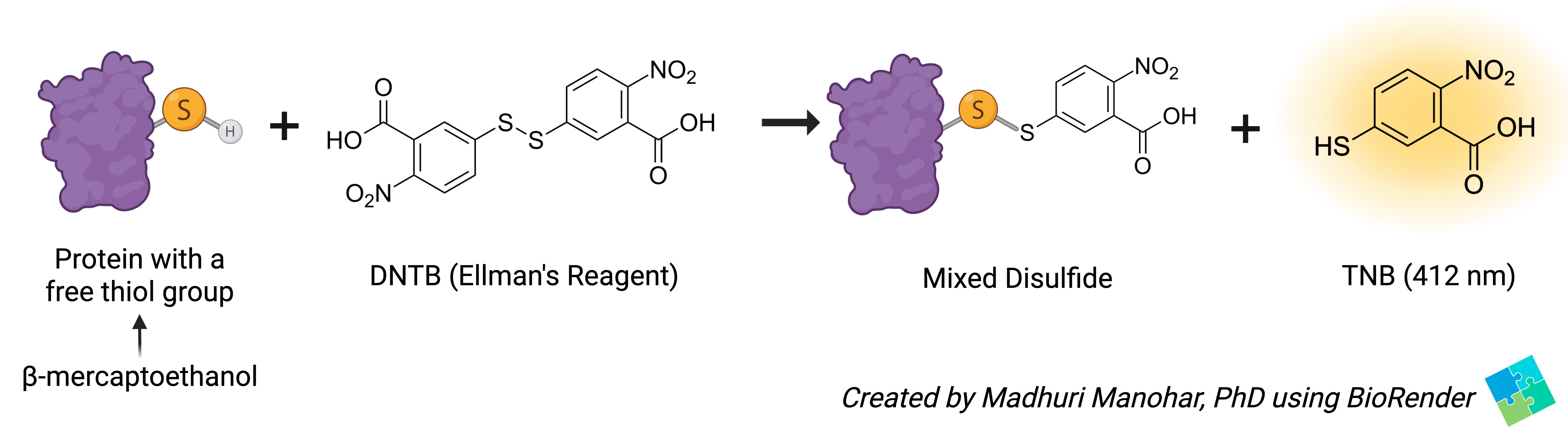
If your protein has cysteine residues that form disulfide bonds integral to its structure and function, checking for their appropriate formation is essential. There are many ways to do so: mass spectrometry, NMR, Raman/FTIR spectroscopy, circular dichroism, SDS-PAGE, and more. Most of these require expensive instrumentation, take time, and are better suited for validation. A really quick way of estimating disulfide bond formation is the Ellman’s assay, run in a 96-well plate format.
Pioneered in 1959 by George L. Ellman, the assay specifically measures free sulfhydryl (thiol) groups. Ellman’s reagent (5,5’-dithio-bis-(2-nitrobenzoic acid), known as DTNB) reacts with free sulfhydryl groups to form a yellow-colored product measurable by absorbance at 412 nm. Importantly, checking for disulphide bond formation in proteins is a negative reaction wherein no yellow-colored product indicates that disulphide bonds are present in the native folded protein. Cleaving those bonds using β-mercaptoethanol (BME) denatures the protein, exposes the thiol groups, producing a measurable yellow signal at 412 nm.
Thus, the Ellman’s assay is a quick, quantifiable way of measuring disulphide bond formation, before proceeding to the more-involved validation methods mentioned above.
Tip: Since this is a negative reaction, always include a negative and positive control (L-cysteine in this case). Another indicator that the assay is functioning correctly is the isosbestic point at 356 nm, the wavelength reported in literature for the Ellman’s reagent. At the isosbestic point, reactants and products are at equal concentrations and in equilibrium.
Check out Ellman’s 1959 paper to know more. I also found this protocol quite useful that I adapted for my PhD research.
4. Antibody Spotlight
Science released an article just a few days back talking about how the similarity in names between two proteins has created an antibody mix up that is potentially affecting the science and data on 300+ research papers. Yikes! Researchers who intended to buy antibodies against p16INK4a may have bought antibodies against p16-ARC instead. Oopsy! p16INK4a is a tumor suppressor protein that regulates the cell cycle by inhibiting CDK4 and CDK6, while P16-ARC regulates the cell’s cytoskeleton by controlling actin polymerization.
Where this is problematic?
Some researchers reported results that only made sense with the correct antibody, suggesting that data was possibly shaped to fit expectations. With many of these papers cited hundreds of times, the misinformation is already compounding, and if ingested by AI systems, flawed findings could be treated as ground truth and propagated even further. Mistakes in peer-reviewed papers are easy to find but very hard to fix.
Where this is easily fixable?
Some teams simply listed the wrong product code in their methods section while actually using the right antibody, as confirmed by purchase receipts and lab notebook records, without impacting data integrity. Another reason why good documentation practices must be mandated not just in clinical labs, but even in academic labs.
Where we shall never know?
Think of all those abandoned results and experiments that never saw the light of the day because the wrong antibody was used. Real valuable scientific data that could have come out of those experiments! I guess we’ll never know.
To read more about it, check out the article on Science as well as detailed analysis on the For Better Science blog.
5. In Silico
When I sat in the AI x Bio conference listening to all the distinguished speakers, I realized the breakneck speed of the use of artificial intelligence in biology. From DNA to RNA to protein applications, from compressing drug discovery timelines to understanding the molecular dynamics better, from allowing old problems to disappear to creating novel binders for undruggable targets, the AI research is galloping at a rate faster than I can comprehend. The amount of models out there with each having its unique advantages and datasets, and caveats and limitations - the research is mind-boggling. Whenever I feel so, I just sit down with a good old review paper (and my coffee) and get on with my reading. Of all the solutions AI is being applied in biology, my core interest has always been protein design. To get to know more, I chanced upon this article from the David Baker lab (2024 Nobel Laureate in Chemistry) that details de novo protein design. Check out the article on this link to know more.

6. Antibody Term of the Week
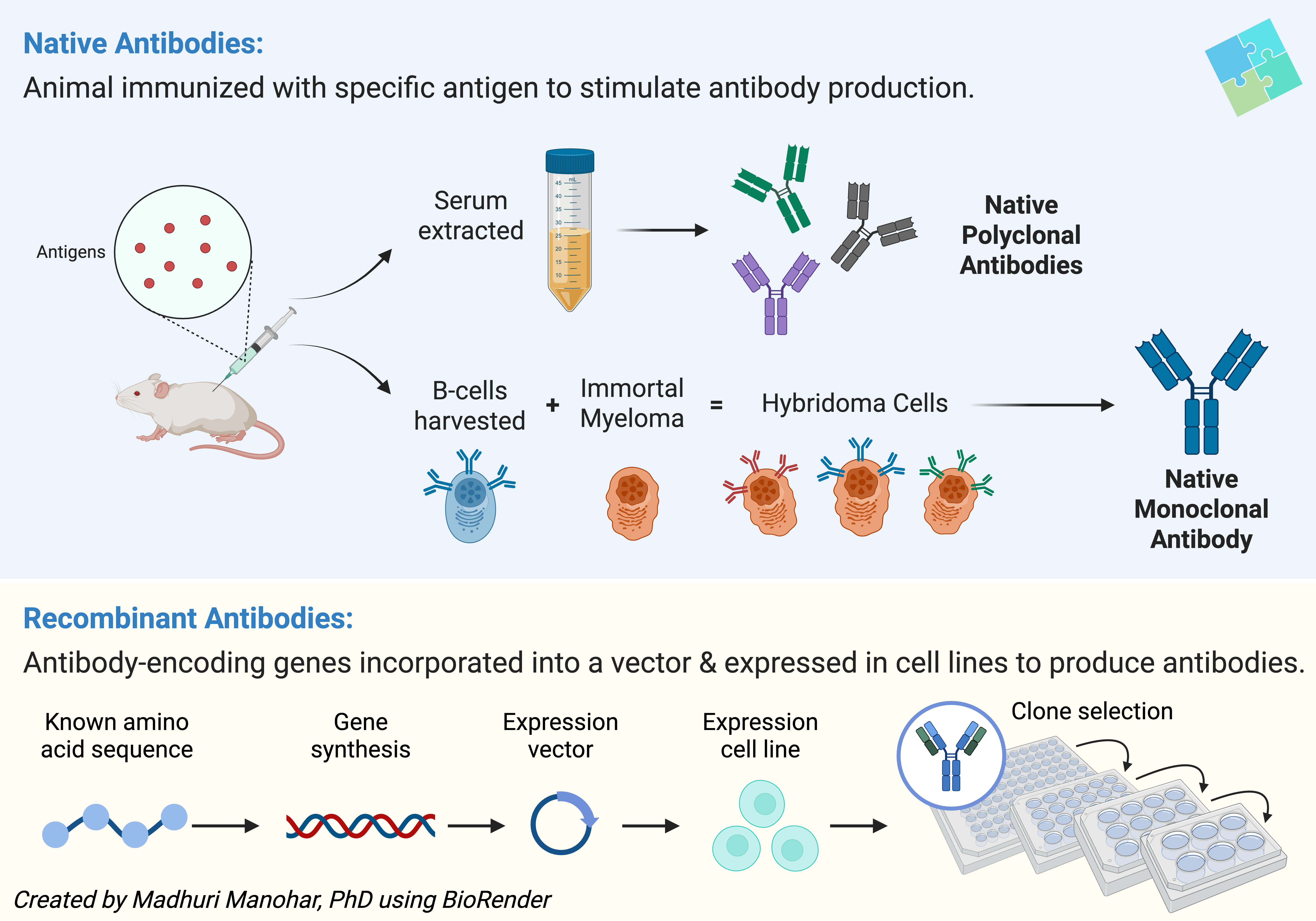
This week we delve into native versus recombinant antibodies. Native antibodies are sourced from a biological source, either from immunized animals or traditional hybridoma cell lines. Recombinant antibodies, on the other hand, are synthesized using recombinant DNA technology by cloning the genes encoding the heavy and light chains of the antibody into expression systems. Native antibodies are inherently variable as they could be polyclonal or monoclonal. However, recombinant antibodies are highly reproducible and are well-defined monoclonal antibodies. Think of it like a tailor-made suit versus an off-the-rack blazer. They both fit, but one is made just for you.
I hope you all enjoyed this edition of The Binding Brief. If you have suggestions for topics you’d like to know more about… ⤵️
This site is free and I intend to keep it that way for as long as I can because good science communication should be accessible, especially for students. If you enjoy what you read and feel like buying me a coffee along the way, I won't say no. ☕ And if you're not a student, consider paying it forward to one who is.
This week, I signed up for a BioRender license so that I could make precise, descriptive, and beautiful images for you. I hope you like them! 😊
They are visually better on the desktop than for viewing on the mobile app. Something I shall keep in mind for next time.